 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP8-RL: A Practical and Stable Low-Precision Stack for LLM Reinforcement Learning
Jan 26, 2026Reinforcement learning (RL) for large language models (LLMs) is increasingly bottlenecked by rollout (generation), where long output sequence lengths make attention and KV-cache memory dominate end-to-end step time. FP8 offers an attractive lever for accelerating RL by reducing compute cost and memory traffic during rollout, but applying FP8 in RL introduces unique engineering and algorithmic challenges: policy weights change every step (requiring repeated quantization and weight synchronization into the inference engine) and low-precision rollouts can deviate from the higher-precision policy assumed by the trainer, causing train-inference mismatch and potential instability. This report presents a practical FP8 rollout stack for LLM RL, implemented in the veRL ecosystem with support for common training backends (e.g., FSDP/Megatron-LM) and inference engines (e.g., vLLM/SGLang). We (i) enable FP8 W8A8 linear-layer rollout using blockwise FP8 quantization, (ii) extend FP8 to KV-cache to remove long-context memory bottlenecks via per-step QKV scale recalibration, and (iii) mitigate mismatch using importance-sampling-based rollout correction (token-level TIS/MIS variants). Across dense and MoE models, these techniques deliver up to 44% rollout throughput gains while preserving learning behavior comparable to BF16 baselines.
AIConfigurator: Lightning-Fast Configuration Optimization for Multi-Framework LLM Serving
Jan 09, 2026Optimizing Large Language Model (LLM) inference in production systems is increasingly difficult due to dynamic workloads, stringent latency/throughput targets, and a rapidly expanding configuration space. This complexity spans not only distributed parallelism strategies (tensor/pipeline/expert) but also intricate framework-specific runtime parameters such as those concerning the enablement of CUDA graphs, available KV-cache memory fractions, and maximum token capacity, which drastically impact performance. The diversity of modern inference frameworks (e.g., TRT-LLM, vLLM, SGLang), each employing distinct kernels and execution policies, makes manual tuning both framework-specific and computationally prohibitive. We present AIConfigurator, a unified performance-modeling system that enables rapid, framework-agnostic inference configuration search without requiring GPU-based profiling. AIConfigurator combines (1) a methodology that decomposes inference into analytically modelable primitives - GEMM, attention, communication, and memory operations while capturing framework-specific scheduling dynamics; (2) a calibrated kernel-level performance database for these primitives across a wide range of hardware platforms and popular open-weights models (GPT-OSS, Qwen, DeepSeek, LLama, Mistral); and (3) an abstraction layer that automatically resolves optimal launch parameters for the target backend, seamlessly integrating into production-grade orchestration systems. Evaluation on production LLM serving workloads demonstrates that AIConfigurator identifies superior serving configurations that improve performance by up to 40% for dense models (e.g., Qwen3-32B) and 50% for MoE architectures (e.g., DeepSeek-V3), while completing searches within 30 seconds on average. Enabling the rapid exploration of vast design spaces - from cluster topology down to engine specific flags.
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020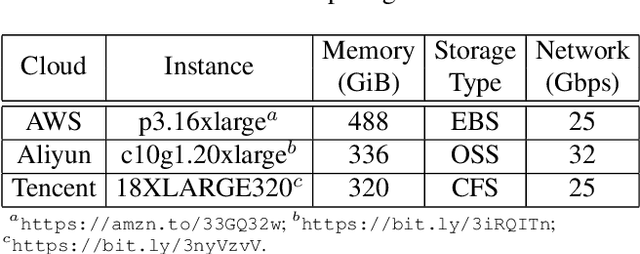
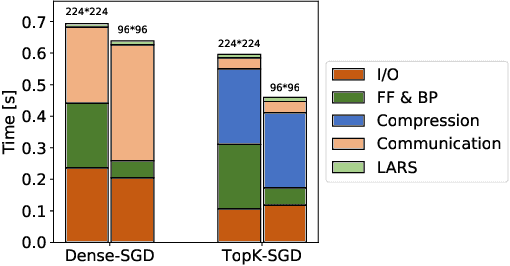
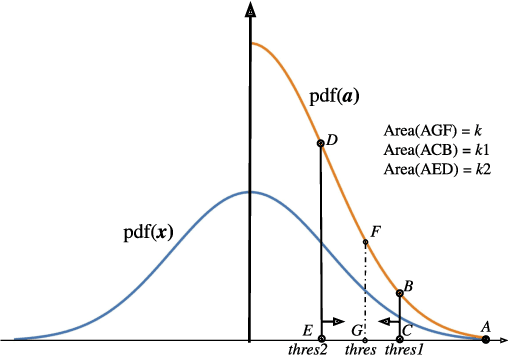
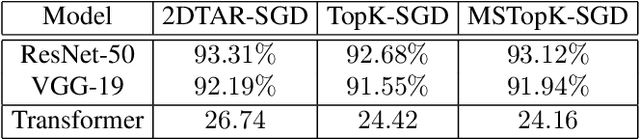
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.